We’re hiring! Join our mission to build the foundation for the agentic world. See Open Roles ->
[
]
Measuring Reasoning with Evalchemy
If you can't measure it, you can't improve it. Releasing reasoning benchmarks into our model evaluation tool Evalchemy

If you can't measure it, you can't improve it. At Open Thoughts, we are on a mission to build the best open reasoning datasets (and therefore, the best open reasoning models). We are sharing everything publicly on our journey including the tools we are using to get there. Today we are releasing reasoning benchmarks into our model evaluation tool Evalchemy.
Model evaluations are the important feedback signal in the experimental feedback loop. Measuring the effectiveness of a particular data curation strategy allows us to know what works and what doesn't. These evaluations need to be reliable, repeatable, easy to use and fast. This is why we built Evalchemy.
Evalchemy is a unified interface for evaluating post-trained LLMs. Built off the popular lm-evaluation-harness by EleutherAI, we have added additional benchmarks and support for evaluating more API-based models.
As part of the Open Thoughts project, Evalchemy now includes the common reasoning benchmarks AIME24, AMC23, MATH500, LiveCodeBench, and GPQA-Diamond. Coding evaluations HumanEvalPlus, MBPPPlus, BigCodeBench, MultiPL-E and CRUXEval have also joined the expanding list of available benchmarks.
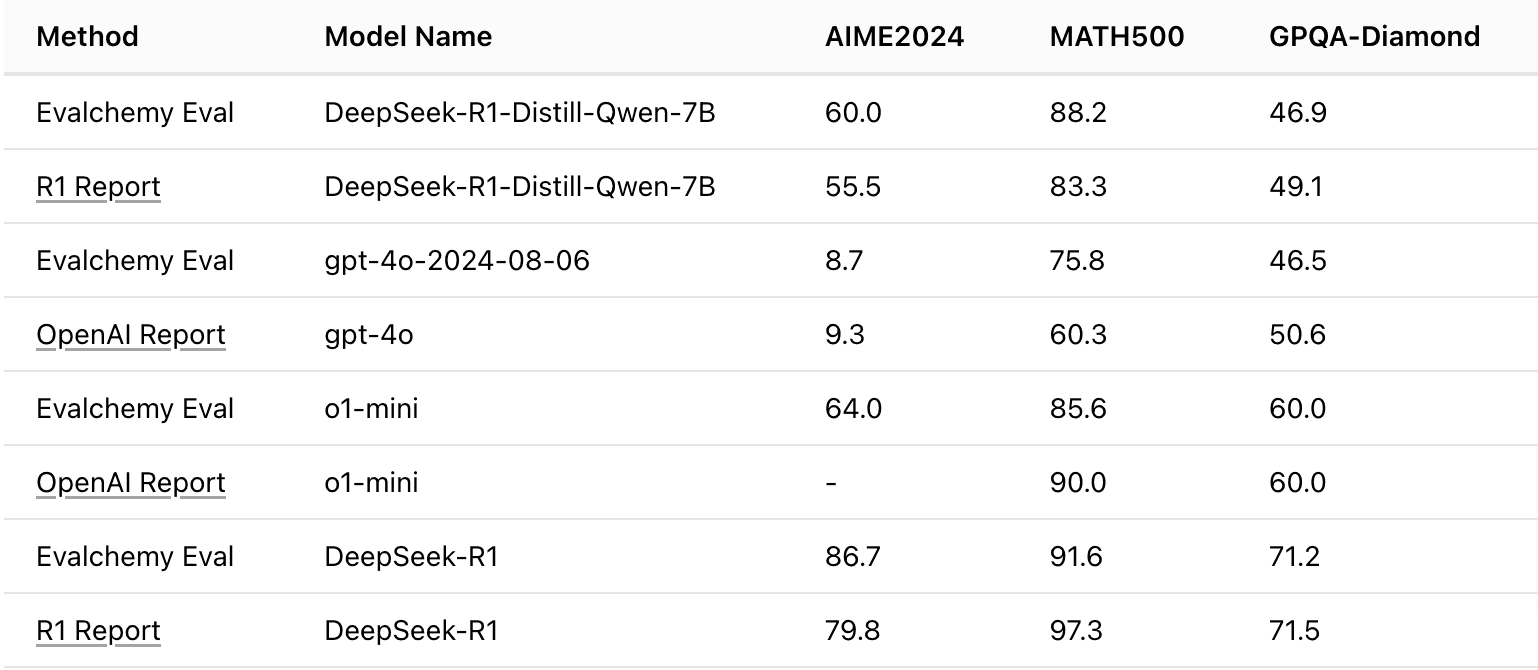
In the table above we show our evaluation results for reasoning benchmarks on popular models compared to the publicly reported numbers.
Note: The AIME24 dataset has a small sample size, resulting in high variance in evaluation accuracy. To mitigate this, we updated the code to compute the average score over five evaluation runs with different seeds. No system prompt is used, the maximum token length is set to 32,768, and temperature = 0.7.
We are continuously improving Evalchemy. If there is a benchmark you would like to see added, please raise an issue on Github, or even better, open a pull request, as we encourage contributions from the community.
Cross-posted from www.open-thoughts.ai/blog/measure
Share