We’re hiring! Join our mission to build the foundation for the agentic world. See Open Roles ->
[
]
OpenThinker is a decensored reasoning model


DeepSeek announced DeepSeek-R1 about a month ago, bringing reasoning to the forefront. While DeepSeek open-sourced DeepSeek-R1 with an MIT license and the various distilled models, it did not provide the data used to train the models, and the models themselves were aligned with CCP’s values (some people call these models censored models).
We set out to fix the first aspect with OpenThoughts but inadvertently broke the second. The OpenThinker models appear to be decensored (but not unaligned).
Perplexity announced a decensored R1 model yesterday, so we thought providing more details about the decensored OpenThinker models we announced earlier would be good.
Political Decensoring
What’s fascinating about our decensoring methodology is that — there was none. We created an open reasoning dataset consisting of Math, Coding, and graduate-level questions and answers and announced it as OpenThoughts-114k (curator viewer). This dataset has been well received (it’s trending on HuggingFace), and crucially, it doesn’t have any political questions that aim toward decensoring (to the best of our knowledge).
With this dataset, we trained two models, a 7B-sized model called OpenThinker-7B (announced on Jan 28) and a 32B model called OpenThinker-32B (announced last week on Feb 12). In particular, the 32B model is an excellent reasoning model for its size and beats DeepSeek’s corresponding distilled model in a few benchmarks.
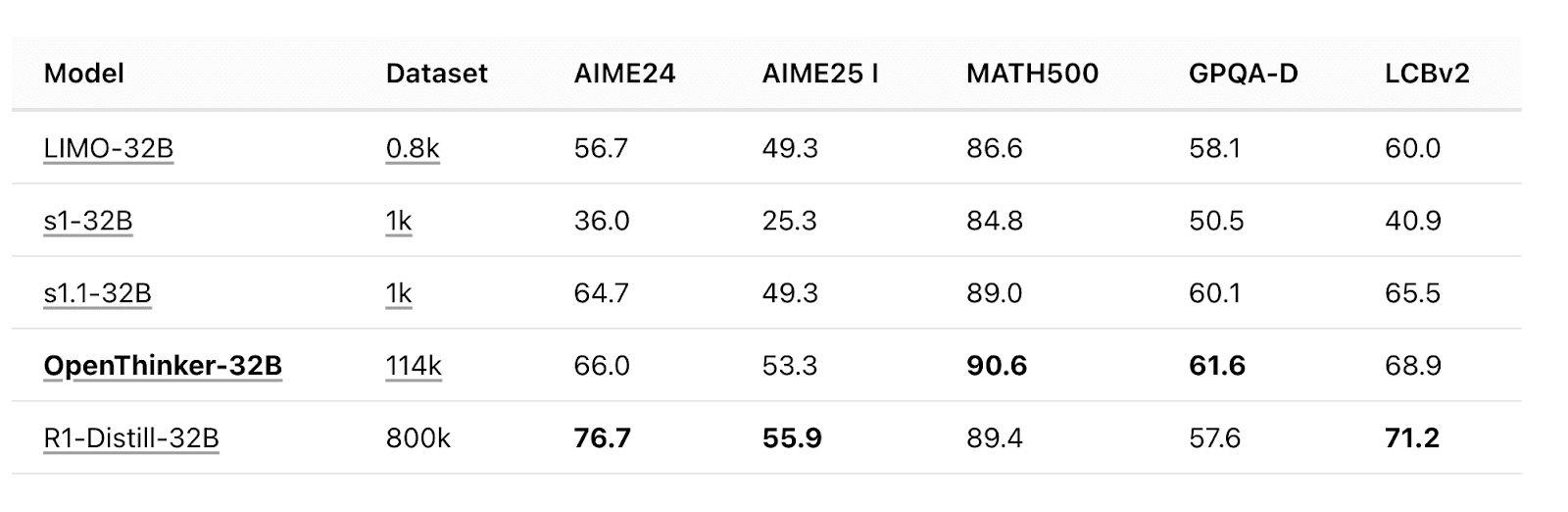
Unlike Perplexity, we didn’t have to do any custom fine-tuning to remove political censoring. Our finetuned models are already decensored.
Interestingly, Qwen’s Instruct models, which we used as the base model to fine-tune, are censored (and aligned, i.e., no unsafe responses). DeepSeek-R1, which we used to generate the OpenThoughts-114k data, is also censored (and aligned). DeepSeek's distilled model (noted as R1-Distill-32B) is also censored and aligned. However, by fine-tuning Qwen on DeepSeek-R1’s data, we get a model that appears to be decensored (and aligned!). This, we believe, opens a new line of research. A closely related work is "Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!". However, they mention finetuning affects safety, and the model can become misaligned. However, OpenThinker models seem to refuse to answer harmful and unsafe questions.
You can see the responses of the Qwen2.5-7B-Instruct, DeepSeek-R1-Distill-Qwen-7B, and OpenThinker-7B model side by side on the curator viewer here. We see that Qwen aligns entirely with CCP’s views, while DeepSeek’s answers are pretty measured (and not thoroughly censured). OpenThinker is a lot more straightforward.
Model Availability
As of last week, these models are also available on HuggingFace (7B, 32B). On, Ollama the models have already gotten around half a million downloads. It's pretty easy to play with them if you have Ollama:
We have a hosted instance of it available for testing on our playground and are looking for feedback.
About the effort
This is a DataComp and Bespoke Labs community effort to curate the best open reasoning datasets (and the corresponding models). See open-thoughts.ai for more information. We thank Qwen and DeepSeek for making models available with permissible licenses.
Share