We’re hiring! Join our mission to build the foundation for the agentic world. See Open Roles ->
[
]
Announcing winners of Reasoning Datasets Competition
From 150 innovators emerged 70 unique datasets across 25 diverse domains - from finance and medicine to ethics and gaming; meet the standouts pushing LLM reasoning to new frontiers.

Over the last month, BespokeLabs, Hugging Face, and Together AI set out to discover the most innovative reasoning datasets and the response blew us away.
150+ builders from every corner of the globe
70 original datasets
covering 25 diverse domain
Countless creative pipelines and data-generation tricks we can all learn from. Check out all submission here
After a spirited review and some very tough judging calls, we’re thrilled to announce the winners

1st Prize - Personal Finance by Akhil Theerthala🥇
🎁 Award: $1500 Giftcard + $1500 Together AI credits + HuggingFace PRO
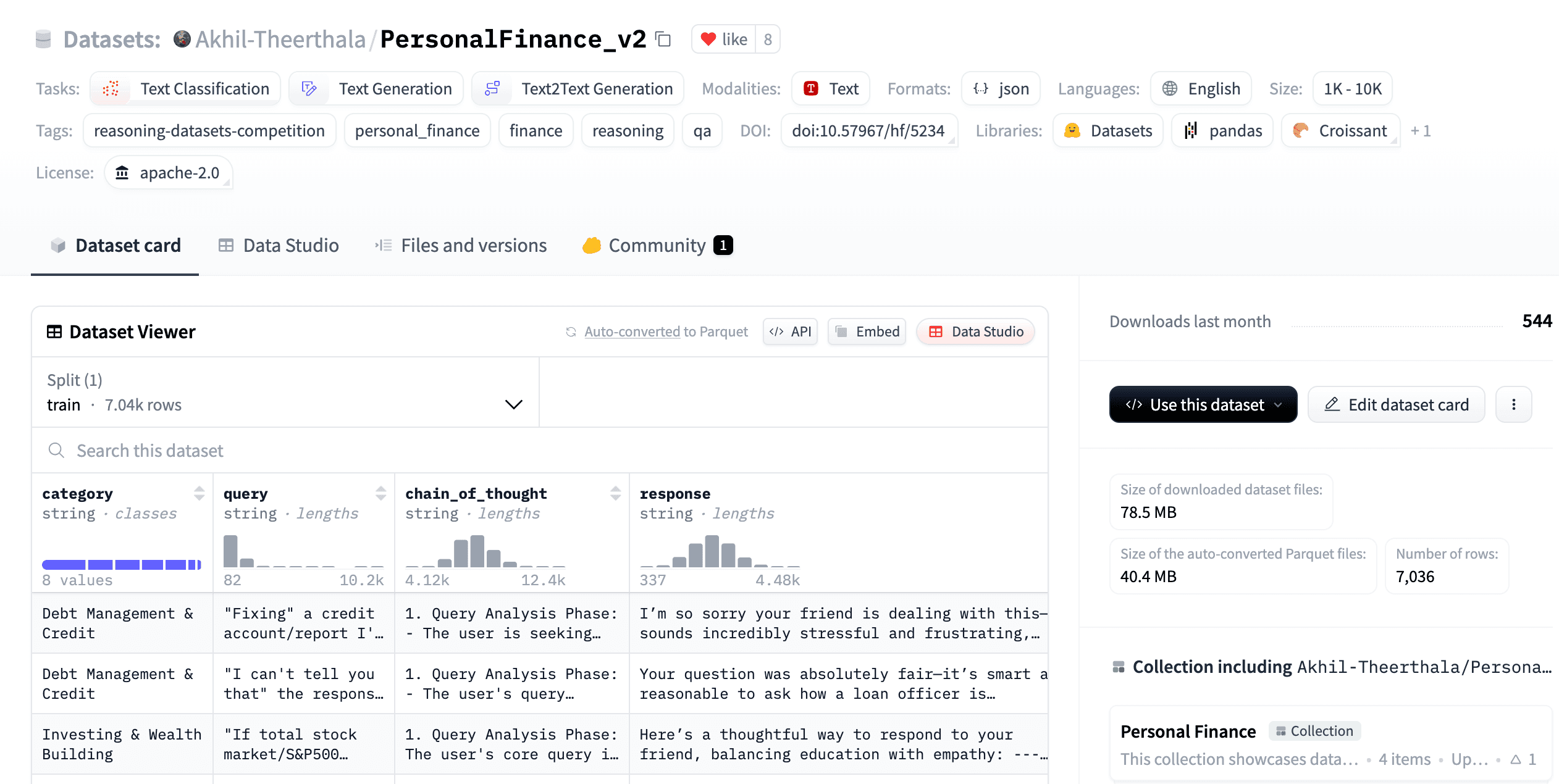
This dataset offers a specialized benchmark for evaluating LLM reasoning in delivering personalized financial advice
Multi-stage pipeline: psychological-intent extraction → RAG context retrieval → LLM-jury filtering, yielding empathic, context-rich advice 🧠
Domain: Reddit r/personalfinance Q-A pairs with full chain-of-thought across 8 topics (budgeting, debt, taxes, investing, retirement, insurance, income, estate) 💸
Evaluations: GPT-4o-mini, DeepSeek-v3 & Gemini-Flash run 5-shot cross-model votes to select the highest-quality response for each query ✅
Check it out here
2nd Prize - WildSci by JustinTx 🥈
🎁 Award: $500 Giftcard + HuggingFace PRO
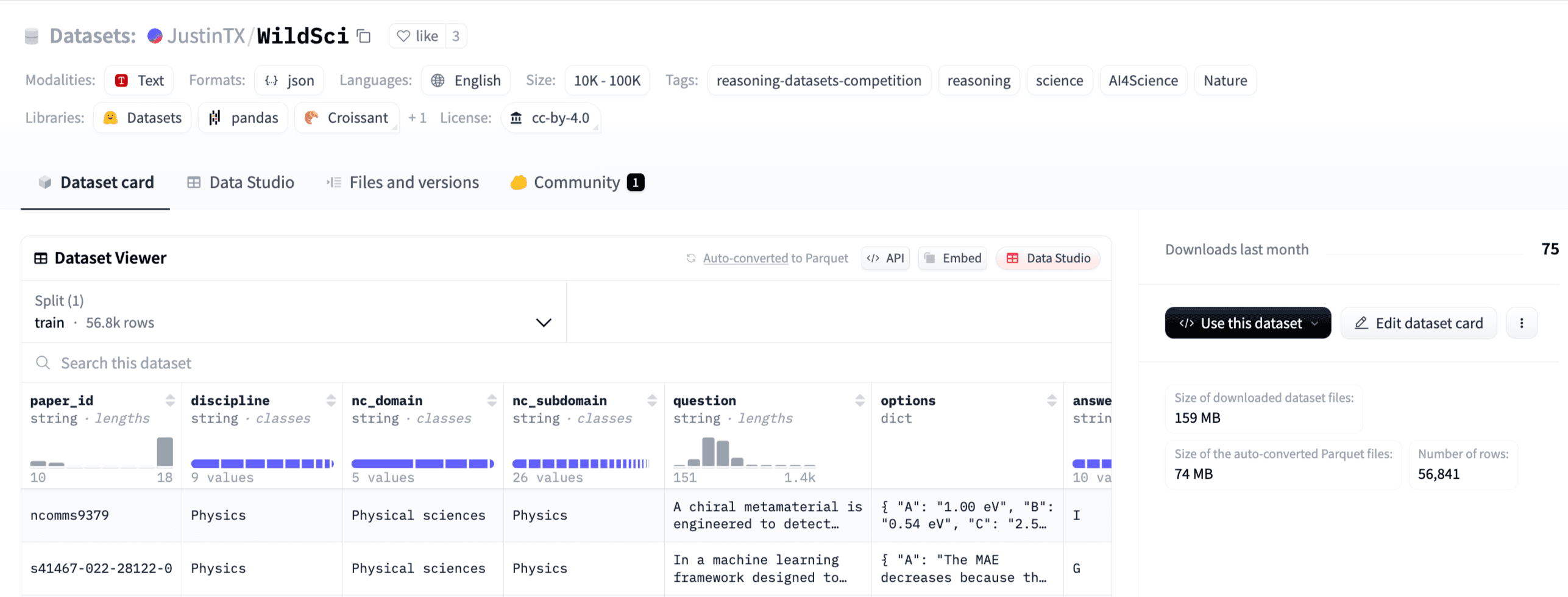
Advancing Scientific Reasoning from In-the-Wild Literature
Multiple-choice Q-A pairs with full, step-by-step rationales for every problem 🧠
9 scientific disciplines, 26 sub-domains mined from peer-reviewed Nature Communications articles 🌍
10 options per question + gold answer and majority-vote labels to stress-test model judgment ✔️
Check it out here
3rd Prize- MedReason by UCSC-VLAA 🥉
🎁 Award: $500 Giftcard + HuggingFace PRO
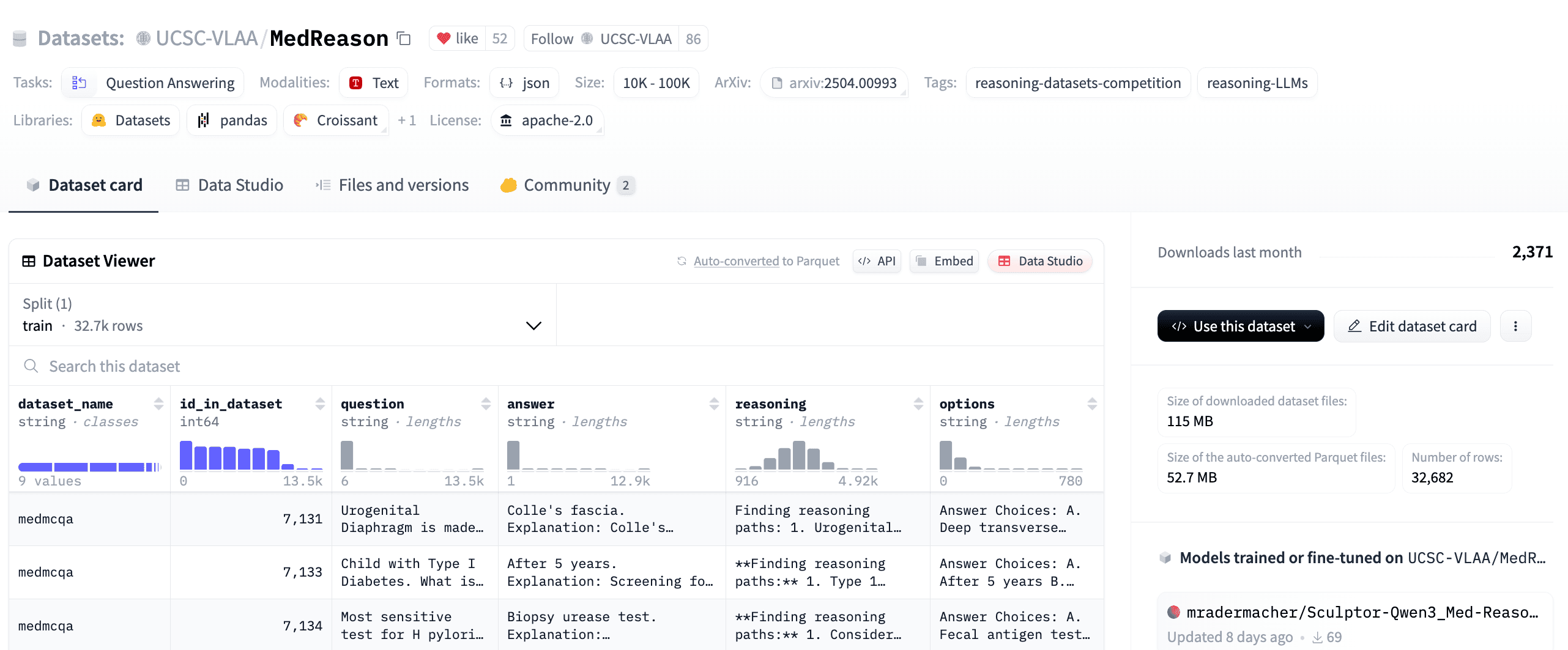
This dataset is designed to enable faithful and explainable medical problem-solving in large language models (LLMs)
Clinical QA pairs drawn from 7 public medical datasets, spanning diagnosis, treatment, biochem & more 🏥
Utilize a structured medical knowledge graph (KG) to convert clinical QA pairs into logical chains of reasoning, or “thinking paths”, and auto-verifies each chain-of-thought for factual consistency 🧠
Clinician-vetted CoT data
Check it out here
Wait there are more prizes...
Spotlight on the best use-cases of Bespoke Curator
🎁 Award: $250 Amazon giftcard each
To showcase how builders are already putting Bespoke Curator to work, here are four standout use‑cases.

Check out these datasets here
Some more Honourable Mentions
🎁 Award: HuggingFace Pro Annual Subscription
A special shout‑out to these creative participants who impressed the judges. We loved their submissions and want to extend our support in scaling the work

Gratitude Where It’s Due ❤️
A massive thank you to our partners @huggingface, @togethercompute and to our amazing judges. Your feedback raised the bar for transparency, creativity, and reproducibility.
What’s Next?
🏅 Winners: We’ll reach out in the week of 21st May to arrange prizes.
📂 Browse all submissions here
💬 Join the conversation: Ask anything in our Discord community
Whether you’re building the next benchmark or just curious about how LLM reasoning can evolve, we’d love to have you along for the ride.
See you in the next challenge!
Share